This is the first entry in a series on Elasticsearch and how we use it in Zumba’s applications.

Many of Zumba’s applications have some form of search. In the beginning, many of these were implemented via querying MySQL. As you can imagine, this doesn’t scale very well. On top of that, certain types of queries, such as geo location, are difficult to accomplish (read: we have to do math). As we grew and our search volume steadily increased, we realized we needed to do something to improve scalability. After some research, a decision was made to use Elasticsearch to solve these issues.
As you probably inferred from above, MySQL is the database we use for permanent storage. I’ll be using Elasticsearch as an ephemeral storage throughout this series. This means, we must have a process that will translate our relational data into a document format that Elasticsearch can understand and use.
This involves building an index in Elasticsearch. Any query/search a user would perform would be executed against this index. This presents a new challenge: how do we accomplish rebuilding an index that users are actively using?
The graph below shows what would happen if we were to rebuild the index directly: disruption and incomplete data.
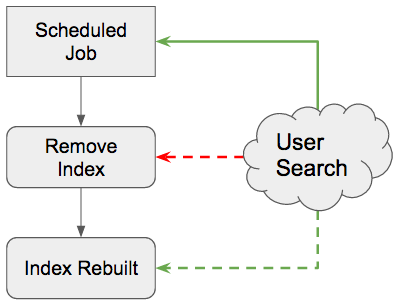
Rebuilding an index causes total disruption initially and incomplete results until the index is fully rebuilt.
We solved this issue by implementing a rotating index. Instead of removing the active index, we create a brand new index, build it, and then swap the “primary” index that the users are actively searching.
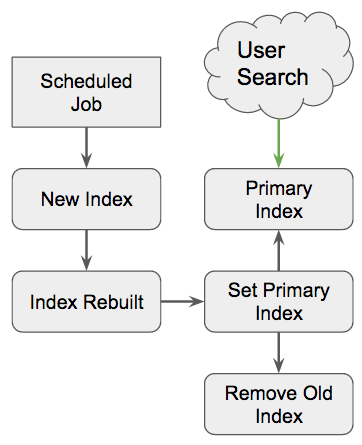
Here the user’s search is never disrupted because we construct a new index and after it is built/settled, we change the what index to search by the client.
With our solution the index name becomes dynamic. There are two possible ways to deal with having the client know which dynamic index is the “primary”. In both of the following cases, assume we just created a dynamic index for searching locations named “locations_12345”.
Alias Approach
An alias can be created for a common index name that will always point to the primary index. With Elasticsearch’s “_alias” endpoint, I can create an alias called “locations” on “locations_12345” which would enable the application to do:
GET locations/location/_search
which is equivalent to:
GET locations_12345/location/_search
It was pointed out to me by Zachary Tong from Elastic.co that you can swap out the old and new alias when rotating indices in an atomic fashion:
POST /_aliases
{
"actions": [
{ "remove": { "index": "locations_*", "alias": "locations" }},
{ "add": { "index": "locations_12345", "alias": "locations" }}
]
}
Configuration Approach
In this approach, you create a special index that is fixed that contains a list of all indexes created for the “locations” dynamic index. Only one entry in this index has the “_id” of “primary” which is what the client would query prior to querying the dynamic index.
The client would make a request to the configuration index.
GET .locations_configuration/configuration/primary
The result would contain “locations_12345”. It also has the added benefit of storing a list of the old indices that we can delete later. The downside of this approach is that you need to make two requests to Elasticsearch — one to get the dynamic index from the configuration index, and one to perform the actual query. However, eliminating search disruption out-weighs the overhead of multiple requests in our use-case.
If you would like to see (and use) our implementation of these index rotation strategies, I recently open-sourced our Elasticsearch index rotation library.
In the next installment of this series I will cover our applications that specifically use Elasticsearch and what sort of queries/mappings these application features require.


